🐛 🐛 NVIDIA NemoTron and Automodel Bug-hunting
For a class project at UC Berkeley, my group and I were tasked with pre-training NemotronH (a hybrid mambda-transformer MoE) without checkpoints, using NVIDIA’s Automodel training framework. This seems like a pretty expected flow as NemotronH is an NVIDIA model and Automodel is an NVIDIA training framework/library, but we ran into a few hiccups that taught us a lot about how NVIDIA structures their repo as it’s pretty opinionated/biased towards a few workflows. These are bugs that specifically on the NVIDIA Automodel repository. Also this is probably a super common bug (NaNs in training loop) but learned a lot from it!
Automodel repository itself also has a good amount of pretraining recipes, alongside posttraining. It makes sense that NVIDIA expects people to use the from_pretrained path, which works great because the typical workflow is download someone’s weights from HuggingFace then finetune.
This log is inspired by Daniel Han from Unsloth’s Gemma bug fixes post! Also obligatory I love NVIDIA! Thank you for the compute
Mystery problem
We ran into a mysterious bug while running our NemotronH 30B-A3B config through Automodel. Starting at step 0 in the first forward pass, we’d get loss=NaN and grad_norm=0.0 no matter what. The framework would not yell anything or throw any assert errors.
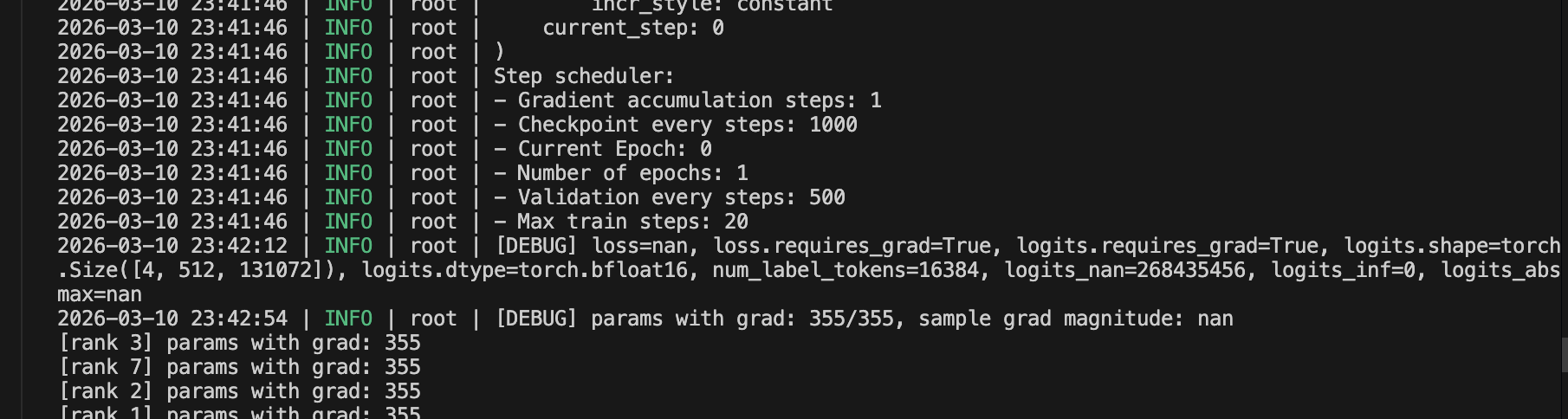
Our parameters were being loaded correctly. It wasn’t exploding gradients either. I then added debug prints at the entry points of each layer and narrowed it down to the first Mamba layer was already producing NaN output. Looking into this further, it turned out to be two separate bugs— one in FSDP2’s mixed-precision policy, and one in weight initialization.
Bug 1: Breaking autograd
Automodel supports pretraining but it expects very Hugging-Face coded return types. Automodel is written assuming every model returns a dataclass but NemoTronH doesn’t, so the whole thing silently breaks as in training starts.
When AutoModel’s MoE parallelizer wraps modules with FSDP2, it applies MixedPrecisionPolicy(output_dtype=torch.bfloat16). This tells FSDP2 to call .to(bfloat16) on whatever the module’s forward pass returns. HF models return CausalLMOutput dataclasses, where the cast propagates through tensor fields cleanly. NemotronH returns a raw torch.Tensor and calling .to() on that detaches the autograd graph. Gradients silently become zero and then loss becomes NaN. AutoModel is written assuming every model returns a dataclass but NemotronH doesn’t, so the whole thing silently breaks as in training starts.
So basically, FSDP2 has finetuning-first assumptions baked into the wrapping logic. The mixed-precision policy assumes HF-style return types that not all models follow, and there’s no validation on what comes back from the forward pass. You just get loss=NaN, grad_norm=0.0
Bug 2: init bug leaves garbage memory in parameters
The weight initialization assumes from_pretrained will fill in everything, so initialize_weights() only needs to handle special cases — but when you’re building from config, every parameter needs explicit init
When you pretrain from scratch, AutoModel uses deferred init — no_init_weights + init_empty_weights + FSDP2’s to_empty(). The idea is to avoid materializing the full model on CPU before sharding. But to_empty() allocates GPU memory without writing to it, so parameters contain whatever bytes were already there. AutoModel’s initialize_weights() is supposed to fix this, but it only covers architecture-specific special cases like dt_bias and A_log. Anything it misses, like Mamba’s norm.weight, stays as garbage, and the first CUDA kernel that touches it produces NaN.
As a temporary workaround, I reinitailized all parameters unconditionally before the first forward happens.
We had to write a function that does init all params to something not-garbage as a global fallback, then run the real init on top. should be a way to keep track which parameters have been inited and which haven’t.
The function walks every parameter: normal distribution for weights, zeros for biases, ones for norms, then calls initialize_weights() to overwrite with architecture-specific values where needed.
Yay loss is no longer NaN!
