Vector Addition Worklog on a B200
Over the weekend, I was trying to see if I could use CUDA to speed up a simple task, vector addition, on Tensara. Specifically, the differences between block sizes and noncoalesced/coalesced memory. The kernel ranked 2nd in the B200 category and 4th across all GPUs available on the Tensara platform (L4, A100, H100, B200, etc).
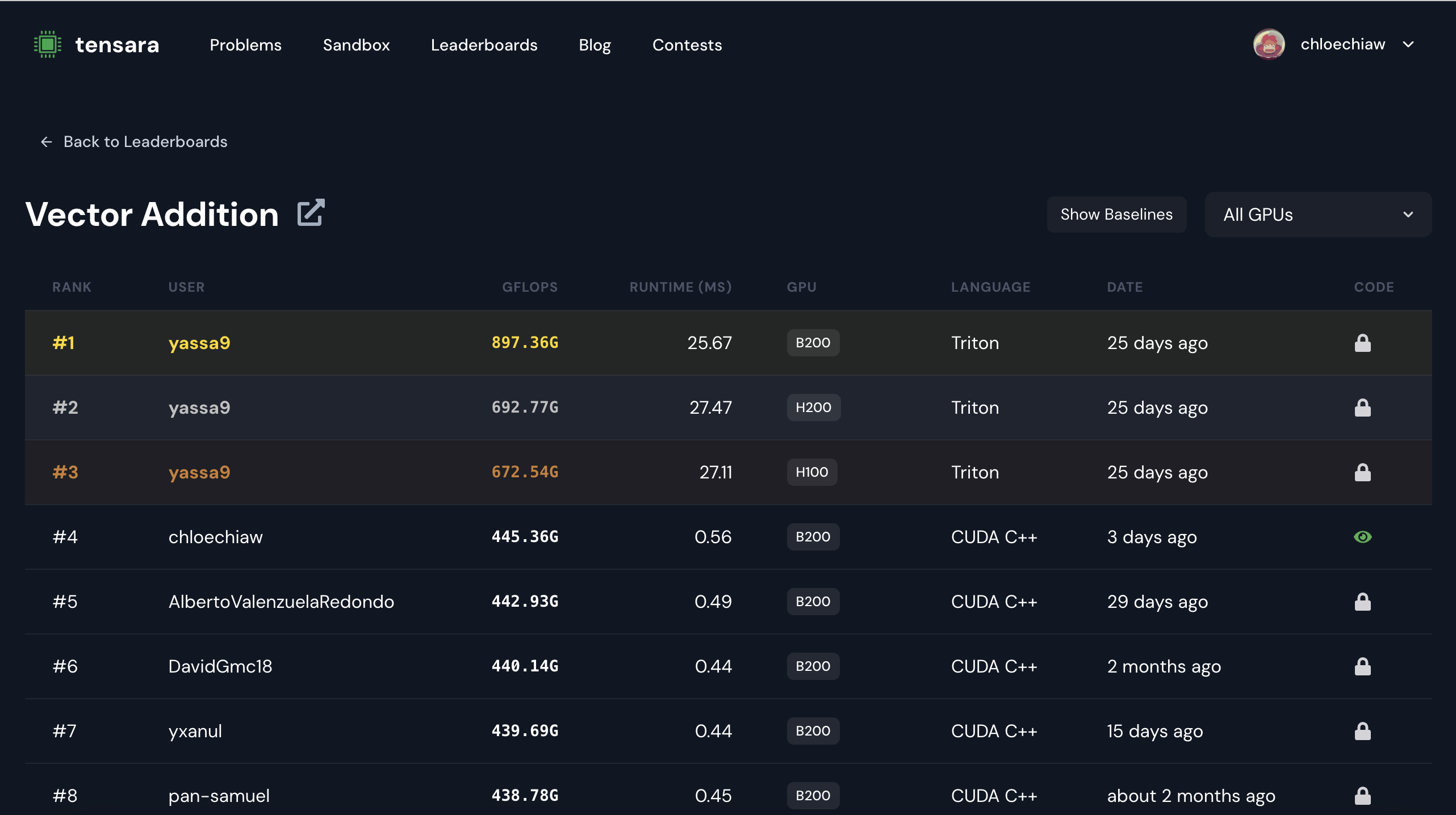
#4/465 submissions across all GPUs and user, yassa9, is absolutely mogging everyone with Triton LOL. There’s a substantial GFLOPs diff compared to everyone else (he has 2x more GFLOPs than my kernel)
I am still learning, so this is a novice worklog describing all the things tried! This post is inspired by this wonderful worklog
TLDR
I was working on optimizing a memory-bound kernel for vector addition on NVIDIA H100 and B200 GPUs.
At first I just played around with low hanging fruit such as block size (since the max is 1024 threads per block on an H100) to see what the performance benefits were but then tried to use more logical approaches such as coalesced memory access. The language I chose was CUDA, but Tensara, the kernels website, lets you submit kernels in Triton, CuTe DSL, etc.
Initial Approach: Multiple Elements Per Thread, Noncoalesced
My first implementation had each thread handle 8 elements (4 from each input array):
__global__ void vectorAdd(float *d_a, float *d_b, float *d_output, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int base = idx * 8;
if (base + 7 < n) {
float4 a1 = reinterpret_cast<float4*>(d_a)[base/4];
float4 a2 = reinterpret_cast<float4*>(d_a)[base/4 + 1];
float4 b1 = reinterpret_cast<float4*>(d_b)[base/4];
float4 b2 = reinterpret_cast<float4*>(d_b)[base/4 + 1];
float4 result1, result2;
result1.x = a1.x + b1.x;
result1.y = a1.y + b1.y;
result1.z = a1.z + b1.z;
result1.w = a1.w + b1.w;
result2.x = a2.x + b2.x;
result2.y = a2.y + b2.y;
result2.z = a2.z + b2.z;
result2.w = a2.w + b2.w;
reinterpret_cast<float4*>(d_output)[base/4] = result1;
reinterpret_cast<float4*>(d_output)[base/4 + 1] = result2;
}
}
This approach used CUDA’s float4 vector type to load 4 floats at once, maximizing the data loaded per instruction. Since CUDA vector types max out at 4 elements, loading 8 elements required two float4 loads per thread.
The Memory Access Pattern Problem
With this approach, the memory access pattern looked like:
Noncoalesced Access Pattern: Thread 0: indices 0-7 Thread 1: indices 8-15 Thread 2: indices 16-23 Thread 3: indices 24-31
Within a warp (32 threads executing together), threads were accessing memory in strides of 8 floats, not consecutively. This meant: Thread 0 loads bytes 0-31 (8 floats) Thread 1 loads bytes 32-63 (8 floats) Thread 2 loads bytes 64-95 (8 floats)
This is a problem because threads in a warp access memory in strides of 8 floats, not consecutively. This causes multiple memory transactions instead of one coalesced transaction, wasting precious memory bandwidth.
Coalesced Memory
Coalesced Access (Optimal): Thread 0: index 0 Thread 1: index 1 Thread 2: index 2 … Thread 31: index 31
All 32 threads in a warp access consecutive memory addresses → 1 memory transaction Noncoalesced Access (My Original Code): Thread 0: indices 0-7 Thread 1: indices 8-15 Thread 2: indices 16-23
Threads access data in strides → Multiple memory transactions Consecutive threads have to access consecutive memory locations
Attempt #1: Adjusting Block Size
My first optimization attempt was just to see how block size tuning impacted GFLOPs.
Testing different thread counts per block:
- 256 threads/block (baseline)
- 128 threads/block (allows more blocks per SM, often good for memory-bound operations)
- 512 threads/block (higher occupancy to hide memory latency)
- 1024 threads/block (max occupancy)
Results on H100:
- 512 and 1024 threads/block: Lower GFLOPS
- 128 and 256 threads/block: Similar performance There wasn’t too much of a difference between changing the block size given that there was poor memory coalescing.
#include <cuda_runtime.h>
__global__ void addKernel(const float* d_input1, const float* d_input2, float* d_output, size_t n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int idx = i * 4;
if (idx + 3 < n) {
float4 a = *reinterpret_cast<const float4*>(&d_input1[idx]);
float4 b = *reinterpret_cast<const float4*>(&d_input2[idx]);
float4 result = make_float4(a.x + b.x, a.y + b.y, a.z + b.z, a.w + b.w);
*reinterpret_cast<float4*>(&d_output[idx]) = result;
}
}
extern "C" void solution(const float* d_input1, const float* d_input2, float* d_output, size_t n) {
dim3 blockSize(512);
dim3 gridSize((n/4 + 511) / 512);
addKernel<<<gridSize, blockSize>>>(d_input1, d_input2, d_output, n);
Result: Around the same GFLOPS and latency as the non-coalesced version with 4 elements per thread.
Even with coalescing, each thread was only doing 1 operation, reducing computational intensity.
Attempt #2: Coalesced Memory + Multiple elements/thread
Turns out you can combine both strategies: coalesced memory access and having each thread process multiple elements:
#include <cuda_runtime.h>
__global__ void addKernel(const float* __restrict__ d_input1,
const float* __restrict__ d_input2,
float* __restrict__ d_output, size_t n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int idx = tid * 8;
if (idx + 7 < n) {
float4 a1 = *reinterpret_cast<const float4*>(&d_input1[idx]);
float4 b1 = *reinterpret_cast<const float4*>(&d_input2[idx]);
float4 a2 = *reinterpret_cast<const float4*>(&d_input1[idx + 4]);
float4 b2 = *reinterpret_cast<const float4*>(&d_input2[idx + 4]);
float4 r1 = make_float4(a1.x+b1.x, a1.y+b1.y, a1.z+b1.z, a1.w+b1.w);
float4 r2 = make_float4(a2.x+b2.x, a2.y+b2.y, a2.z+b2.z, a2.w+b2.w);
*reinterpret_cast<float4*>(&d_output[idx]) = r1;
*reinterpret_cast<float4*>(&d_output[idx + 4]) = r2;
}
}
extern "C" void solution(const float* d_input1, const float* d_input2, float* d_output, size_t n) {
dim3 blockSize(1024);
dim3 gridSize((n/8 + blockSize.x - 1) / blockSize.x);
addKernel<<<gridSize, blockSize>>>(d_input1, d_input2, d_output, n);
}
Instead of each thread accessing 8 consecutive elements (stride of 8), threads now access elements separated by stride (total number of threads).
This ensures: First iteration: Thread 0 → index 0, Thread 1 → index 1, … (coalesced) Second iteration: Thread 0 → index 0+stride, Thread 1 → index 1+stride, … (coalesced)
Each thread still processes 8 elements total (“computational intensity”, although it’s just vector addition so not thatttt intense)
| Implementation | Memory Pattern | GFLOPS (B200) | Notes |
|---|---|---|---|
| Original (8 elem/thread) | Noncoalesced | Baseline | Stride-8 access |
| Single element/thread | Coalesced | ~Same as baseline | Low computational intensity |
| Optimized (8 elem/thread) | Coalesced | Best | Both coalescing + intensity |
Not a kernel expert but even this implementation seems pretty rudimentary. However, I think these problems are a good way to feel like I’m “discovering” these strategies one at a time which makes it more fun!